人類循環中的人工智能實際運作方式
人類循環中的人工智能可讓人們在演算法達到極限的決策鏈中。以下是 HITL 的工作方式以及為什麼重要。

人類循環 AI 是一種模型,人們積極參與培訓,操作或監督人工智能系統,而不是讓它自主運行。
這個概念來自軍事、航空和核能環境,其中自動化系統需要人類干預能力來防止災難。飛行員可以取代自動駕駛。控制器可以中止啟動序列。人類會留在決策鏈中。
AI 借用了這個框架,因為機器學習模型面臨類似的問題。他們在訓練參數中出色的工作。他們在訓練數據沒有涵蓋的邊緣案例、不明確性和情況中都很困難。循環中的人通過在演算法達到極限的地方插入人類判斷來解決這個差距。
這種方法認識到重要的事情。人工智能不應該取代人類。人工智能應增強人類能力。這種組合表現優於單獨工作的任何一種。
人類循環中的人工智能實際運作方式
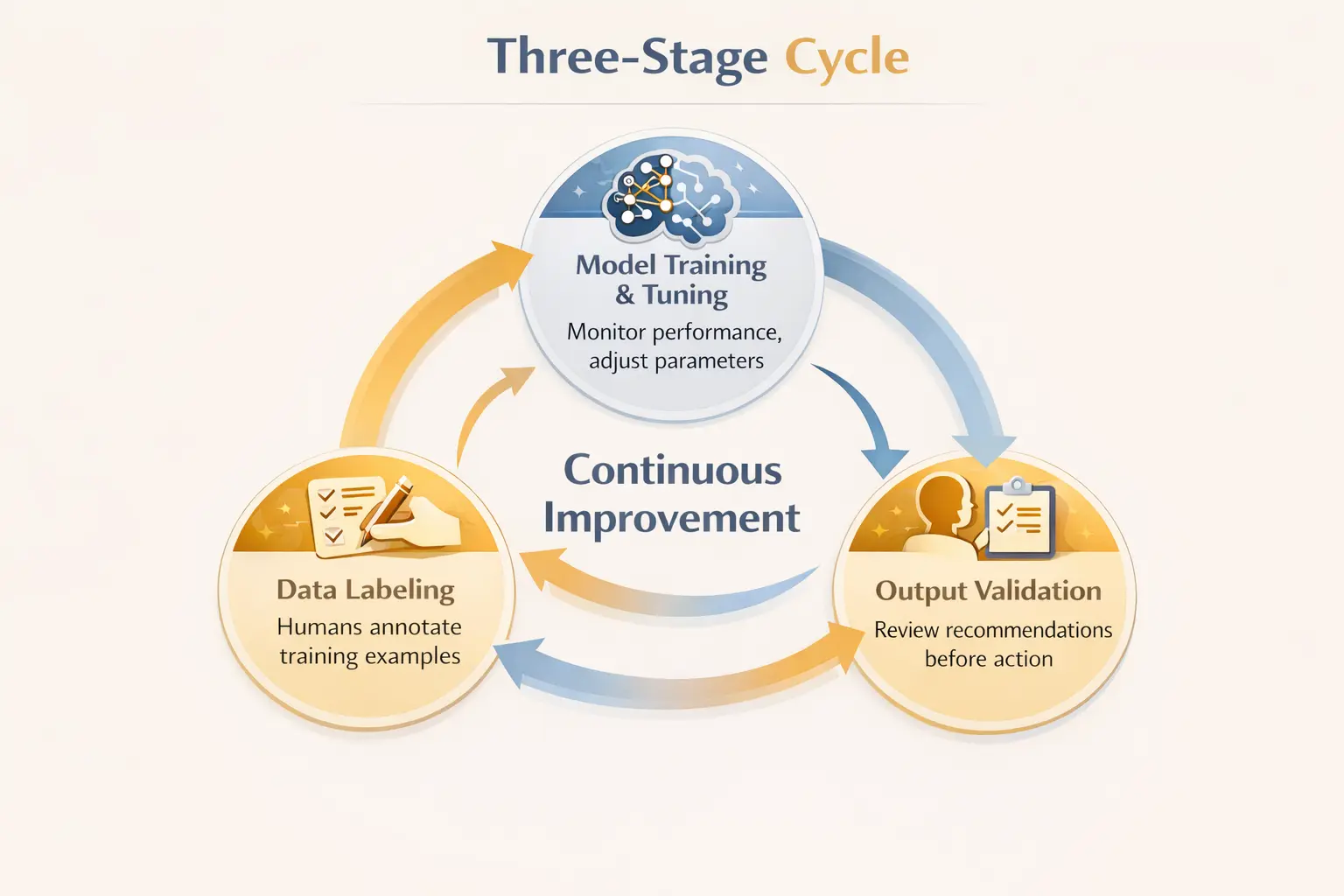
HITL 在人類和機器之間創建了反饋循環。這個週期運作在 AI 生命週期的三個階段。
第一階段涉及數據標籤。機器學習模型從範例中學習。有人必須正確地標記這些例子。在受監督學習中,人類會註釋訓練數據,以教導模型「垃圾郵件」與「非垃圾郵件」的樣子,或者圖像中的哪些像素代表腫瘤與健康組織。根據 IBM ,對於大型數據集來說,這個人為註釋可能很慢且昂貴,但它創造了使機器學習成為可能的基礎。
第二階段涉及模型培訓和調整。人類監控模型的表現。他們得分輸出。他們確定預測出錯誤的地方。它們調整參數。該模型根據人類反饋進行改進,而不僅僅是研磨更多數據。
第三階段涉及輸出驗證。在 AI 建議到達最終用戶或觸發動作之前,人類會對其進行審查。醫生檢查 AI 診斷。內容管理員會審查標記的帖子。金融分析師驗證算法交易信號。人為監督能夠在錯誤造成傷害之前才能偵測到。
這三階段的參與可以帶來持續改進。模型變得更好。人類審核者會了解需要注意哪些錯誤。整體系統比單獨的任何一個元件都更可靠。
為什麼循環人類對人工智能系統至關重要
有幾種力量使 HITL 至關重要,而不是可選。
AI 模型從其訓練數據中嵌入偏見。歷史招聘數據反映過去的歧視。醫療數據集不代表某些人群。金融模式會持續存在的不平等。人類審核者可以識別輸出何時反映這些偏見,並在偏見的建議到達受影響人之前進行干預。
邊緣案例擊敗純自動化系統。真實的情況並不總是與訓練場景相匹配。自動駕駛汽車遇到從未見過的天氣條件。醫療人工智慧面臨其訓練組合以外的症狀組合。自動櫃員機的視覺識別無法讀取手寫支票。當自動化達到其邊界時,人體循環中提供備援能力。
責任需要人類參與。當 AI 犯錯時,有人必須負責。純粹的自主系統會產生責任差距。HITL 確保人類保持在決策鏈中進行後果選擇,保持明確的責任線條。
某些決策需要演算法無法提供的道德推理。 人類 AI 協作 當選擇涉及無法縮減為最佳化函數的值,抵銷或前後關聯時變得重要。人類帶來審判。AI 帶來處理能力。他們一起處理無法單獨解決的問題。
跨行業的人類循環
在人工智能觸及高風險決策的地方,HITL 出現。
醫療保健提供了明確的例子。AI 可以分析醫療圖像,建議診斷並建議治療。但醫生會在採取行動之前審查這些輸出。一 自然醫學編輯 指出,58% 的醫生擔心過度依賴人工智能進行診斷。HITL 通過使用 AI 增強診斷能力的同時將臨床判斷保持在中心來解決這個問題。
內容控制將 AI 偵測與人為審核結合在一起。演算法大規模標記潛在問題的內容。人類主持人對上下文重要的模糊情況做出最終決定。磁碟區需要自動化。細微差異需要人類的判斷。
金融服務使用 HITL 進行欺詐檢測和合規。AI 系統會標記可疑交易。人類分析師會在凍結帳戶或報告活動之前調查旗標。假陽性會傷害無辜的客戶。虛假消息將促進犯罪。人工評估平衡這些風險。
自動駕駛汽車代表不斷演進的 HITL 實施。當前的系統要求人類駕駛員在某些情況下控制。AI 處理日常駕駛。人類處理異常。隨著技術的進步,邊界會改變,但人為監督仍然是安全架構的一部分。
客戶服務越來越將 AI 聊天機器人與人類升級結合。機器人有效地處理常規查詢。複雜或敏感的問題會轉移到人類代理人。混合方法為更多客戶提供服務,同時在最重要的地方保持人際聯繫。

人類循環中的挑戰
HITL 並非沒有缺點。
人類參與會造成瓶頸。AI 每秒可以處理數千個項目。人工審查最大程度每分鐘處理項目。擴展 HITL 意味著招聘許多審核者,或接受只有一個 AI 輸出的樣本受到人類關注。
成本顯著增加。對大型數據集的人類註釋需要數千個勞動小時。醫學或法律等專業領域的專家評審員的成本更高。組織必須平衡準確度增益與預算限制。
人類評論者也會犯錯。疲勞、分心和認知偏見影響人類的判斷力。過度依賴 AI 建議可能會使人類的注意力失去。《自然醫學》一篇關於研究表明,使用 AI 輔助三個月的內視鏡醫生在停止後看到自己的檢測率下降。當 AI 處理過多時,人類的技能可能會衰退。
當人類審查敏感數據時,會出現隱私問題。醫療記錄,財務信息,個人通信。存取這些資料的人類審核人員會產生額外的暴露風險,超出自動化系統才能產生的風險。
Kuse AI 適合人類在循環工作流程中的地方
人類循環人工智能在每個階段都會產生知識。註解準則。模型性能說明。邊緣案例說明文件。評論者反饋。覆寫輸出的決策理由。
這些知識分散在試算表、訓練文件、內部 wiki 和個別審閱者的筆記中。找到您需要的東西成為自己的挑戰。為什麼我們這樣標記這個類別?這款模型遇到哪些邊緣案例?審核者應該如何處理這種模糊的情況?
久瀨 整理這些操作知識,以便 HITL 團隊找到答案,而無需挖掘雜散的文檔。當新審閱者需要註釋指南時,就可以存取它們。當模型重新培訓需要記錄的邊緣案例時,範例存在於一個地方。當有人質疑標籤決定時,可以找到理由。
當他們產生的知識保持有序且可訪問時,人類循環工作流程運行更順暢。
結論
人類循環人工智能代表了完全自動化和手動流程之間的實際中間。機器處理規模和一致性。人類提供判斷、道德和邊緣案件處理。
這種方法有效,因為它發揮了兩者的優勢。AI 可以快速處理大量資料。人類捕捉自動化錯過的東西。它們之間的反饋不斷改善系統。
HITL 不是完全 AI 自主性之前的暫時階段。這是一個可持續的模型,適用於決策過於重要,而不能完全交給演算法的領域。醫療保健診斷。內容控制。財務合規。自動駕駛汽車安全。這些領域可能始終將人類參與循環,因為這些風險要求人類判斷作為後盾。
問題不在於是否要讓人類保持聯繫。問題是如何有效地設計這種參與。工作流程的哪裡?多少評論?評審員提供什麼培訓?支持他們的工具是什麼?
回答這些問題的組織很好地利用人工監督的可靠性來獲得 AI 功能的好處。那些沒有自動化失敗或不可持續的審查瓶頸風險的風險。


